
In software, things are bound to change. Our assumptions crumble, product evolves, naive implementations from the prototype phase fail to scale, libraries and integrated services are swapped. It is our job to make the changes possible, without suffering more stupidly than we have to. Let’s find out which design concepts of hexagonal architecture (a.k.a. ports and adapters) can help us achieve that.
Anticipating changes with DDD
Changes leave an artifact
If you’ve ever been in a situation where you had to incorporate last minute changes, you probably know that changes, especially when done under pressure, leave an artifact in the code: maybe naming no longer makes sense, the documentation is out of date, there is a skipped test nobody knows whether it's safe to delete, a legacy unused enum value that will cost someone 20 minutes to figure out why it was added, when it’s not used anywhere, etc. All of the things mentioned above are avoidable with enough resources, preparation or anticipation.
Some changes are more difficult than others
Another fact about the changes is that some of them are super easy, but some are difficult, difficult, lemon difficult. For example:
- Cut off segment of a large tight monolith so it can be scaled independently: difficult
- Scale independently one service in a well managed monorepo: easy
- Exclude a word from text analyses performed by a 3rd party: hard
- Extend custom existing list of stopwords for text analyses: easy
Sometimes, the difficulty is just because of the conflict with the current solution and had we known about the change earlier, this extra difficulty would simply not exist. If we only knew at the beginning that X should be configurable, we’d not hardcode it; if we knew that API A would have just a fraction of traffic compared to API B, they would not be on the same server so we could scale B differently, if we knew right away we’d need real-time communication we would have used a different communication protocol.
Of course some things are just difficult, because they are inherently difficult.

We can’t do much about the inherent difficulty. What we can do however, is to shift things in our favor, that is, minimize the operational effort caused by the state of the current solution (the effect of technical debt or now irrelevant design decisions): make all changes easy to integrate. The problem is you cannot optimize everything for change and nobody knows what the future holds and if the product knew about changes ahead, they would surely tell you. What should we optimize for change then?
What to optimize for change
Software typically automates, manages or solves real life problems. These can be trivial (sharing photos of cats with friends) but also extremely complex (banking, insurance, logistics, …). The core of the business that exists without the software is the domain and the great thing about it is that it does not change that much! That’s why DDD suggests (pardon the vulgar simplification) that the design of the software and its architecture should be decided by the domain (the objects, functions and structures representing the domain objects and processes) rather than anything else (The very same concept applies in Clean Architecture and others).
Now that we know what “changes less often” and also what is arguably vital for the business, let’s make some generalizations: The domain code doesn't have any dependencies. In other words, in the domain code, you cannot import anything outside the domain (but your other code can import the domain). This is just an (extreme) application of the Stable-Dependencies Principle (SDP), but it has a cool implication: You never need to change your domain code because of external changes. Changing the RESTful API to gRPC does not affect your domain. Changing the database does not affect your domain.
Zero-dependency domain
Having no dependencies in your domain is something that takes some getting used to. For that reason, here are a few key side notes on the topic.
Three-Tier architecture
Yes, this actually contradicts (extends?) the familiar concept of a “layered” or (both relaxed and strict) n-tier architecture. In these classical patterns, your core is protected from the changes from the upper layers (typically UI), but you can easily make your domain layer totally dependent on the base layer (typically data persistence).
Isolating the data layer
Here is my favorite quote that sounds very reasonable, but is (in my opinion) very wrong: If you are building software from the first day with a consideration “What if we are going to need to migrate from MySQL to PostgreSQL?” then there is something fundamentally wrong with your technical planning. I understand it tries to prevent you from overengineering things and makes you Avoid Hasty Abstractions (AHA). The same way you don’t start with architecture or a solution that can handle the future upscale (I bet Netflix did not start streaming on a solution based on hundreds of microservices), you won’t get the storage right. Migrating from one SQL database to another might sound silly, but replacing (typically partly) your data layer is not madness, but usually a necessary and pragmatic step. Here are some examples:
- Move read-only event data from PostgreSQL to BigQuery, once we reach a velocity of thousand inserts per day, compared to couple a week
- Replace “resource locked” indicator from column in SQL to Redis
- And finally: Replace MySQL database with PostgreSQL, because we need to add geo queries, migration is not that painful for us and PostGIS is an excellent choice.
Yes, changing the data layer, even part of it, can be hard. But it gets harder when you need to update your whole domain logic as well.
Saving data from domain
With the knowledge of three-tier architecture, it might sound counterintuitive to make the domain independent of the data layer. How do we save data then? You need to import and call the database object. This is the Inversion of Control (IOC) problem of course: Instead of importing a database into the domain and using it (and being forced to do changes when the database changes), we define (in the domain) an interface we need the database to have and use it. The data layer imports the interface from the domain (dependency is there, but reversed) and implements it.
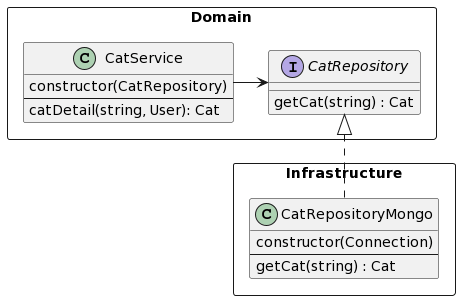
Ports & Adapters
Ports & Adapters are an alternate name for the hexagonal architecture and it describes the second core concept: how to manage the non-domain code.
In hexagonal architecture, the isolated domain communicates with the outside world (API, database, notifications, database, MQ, …) via well defined contracts, which we call ports. Ports are defined in the domain (must be, because they are used by the domain) and they describe the interface of the interaction (in code: interface, abstract class, etc.). Ports have specific implementations (in code: classes implementing or objects conforming to the interface), called adapters (note: yes, it is an implementation of the familiar adapter design pattern).
An example of such a port-adapter pair is a ”Cat Repository”. It defines a behavior to ”get cat”, that returns an object from the domain entity ”cat”. Notice that the domain demands what to work with (inputs and outputs) and defines the behavior of the adapters, albeit on a very abstract level. Cool thing about the isolation and zero outside dependencies is that your domain works regardless of the specific implementation, which allows you to fairly easily swap the adapters and the core of the system remains untouched.

We usually distinguish between primary and secondary “adapters” (if an adapter is secondary, the port is as well, so the attribute could just as well be given to the port, or the port-adapter pair, sometimes referred to as actor). The only difference is where the interaction initiates.
- For secondary adapters, the interaction is initiated by the domain (domain code calls “get cat”)
- For primary (a.k.a. driving) adapters, the adapter initiates the interaction by calling the port (e.g. on empty food bowl the webhook is initiated and port ”Bowl notification” is called with “refill” and domain processes the event)
For primary actors, the adapter pattern does not seem to be as helpful as for secondary and in practice, the isolation can be faked a bit without much loss to the advantages, because you don’t “swap implementations” as you might with the secondary adapters. The distinction is still valid for testability and Interface Segregation Principle (ISP).
Visualizing the domain core as hexagon, the ports as its edges and adapters as bubbles by the edges, you get the familiar graphical representation of the architecture. The author’s article can be found here.

Summary: Why is it worth it and when?
There are two main concepts:
- Separate your domain to be self-sustainable without dependencies;
- Strictly isolate the “outside world” through abstractions and have things plug into your domain, not the other way around.
Adhering yields the following advantages:
- Fast adaptation to adapter changes (changing database, API, 3rd party integration – everything is easier, because the expected behavior is explicit and well defined)
- Easy testability (adapters and domain can be tested separately, domain can be sufficiently tested by unit tests by definition)
- The design of your system makes sense and is not bent to the need of the integration (isolation makes it easier to define your domain the way you want, you can leave all adapter details outside of the domain)
There are few in numbers, but great in significance and will make the difference between “yes” and “no, we must completely rewrite this” in a year in the development.
Following the hexagonal architecture takes a lot of work at first, especially on the domain isolation. You are going to need a lot of abstraction you did not need before and will do much more data mapping and transformations than you used to. What’s more, it feels super awkward on a green-field project, because the data typically looks the same from every angle (e.g. controller, domain, database). That’s alright, resist the temptation to deduplicate. The duplication is there, but an accidental duplication rather than careless or copy-paste duplication. It’s not worth squashing the changes and the rewards will come in due time.
Finally, is the hexagonal architecture worth it every time? When I asked the question at a conference, I heard the opinion that “probably yes (maybe with an exception of some non-domain projects, like drivers, libraries etc.)”. The harsh truth is that the overhead is significant and all the benefits save the changes to the domain, therefore I would not recommend it for projects that are either not going to be maintained (one-time applications) or projects where the adapter complexity would exceed or be comparable to the domain (see anemic domain model), especially for small scale projects. It is a tool that has its place and purpose.
There is a lot of fuzz around the hexagonal architecture. I myself had a lot of questions about it and the more I know about the topic, the more I think details don’t really matter (Should I have services or use case objects? Should I use classes or interfaces? How granular should the ports be?). Read about the concepts and start. Don’t be afraid if you don’t have a reference project for your technology, you will learn it on the fly. That’s why there are no practical tips, but only the core concepts. Here are some recommendations for further reading:
- Introductory article to Hexagonal architecture with examples
- Demo-repository (good for inspiration, few shortcuts, e.g. Queries, breaking the fundamentals, making it hard to recommend for learning the concepts)
- DDD introduction
- Clean architecture summary
- Practical examples article discussing port granularity
- Motivation and high-level introduction talks
Separate your domain code and don’t have any stinking adapter telling you how to interact with it. Farewell and let me know directly or in the comments if you have any questions or would like me to cover more topics!





