
EDIT NOTE: On 28th July 2022, GCP introduced a new option for pushing the messages directly to BigQuery. If you are interested in customization of the data transfer, this blog post might still be useful.
Honestly, whenever you try to google how to send a message from Pub/Sub to BigQuery, you will find many blog posts explaining how simple it is and how Dataflow is the right tool to use. In a small subset of those blog posts, you can find that streaming in Dataflow is not as cheap as batch processing. Therefore, using Dataflow might cost you a few dollars. There is also a template for Dataflow you can use. Since the template deploys GCE instances, your GCP spendings might be higher than expected. Of course, it can be done cheaper. That’s what this blog post is about.
Dataflow implementation
We will only discuss the implementation of Dataflow using Pub/Sub subscription. Having a subscription between a topic and a Dataflow job can be helpful in case you are interested in the messages: you can inspect the messages or set up DLQ. That is especially useful when your Dataflow processing is rather complex. Let’s face it: putting messages from Pub/Sub to BigQuery without any additional work is not a difficult task.
Let’s consider example configuration from terraform module dataflow_pubsub_to_bq. It simply subscribes itself, pulls the messages and then saves them to the BigQuery based on the given BigQuery schema. Due to the way how Beam SDK works, the schema has to be known before deployment:
module "pubsub_to_bq" {
source = "../"
bigquery_schema = "i:INTEGER"
bigquery_table = "${var.project}:${var.dataset_id}.${var.table_id}"
input_subscription = "projects/${var.project}/subscriptions/..."
...
}With the help of PipelineOptions, I changed which machine type is used to e2-medium. Shared core machine types are not currently supported. Using e2-medium is the cheapest option possible. If you wouldn’t set a different machine type, Dataflow would set it to the n1-standard-2. Just like that, you are already paying for a machine you hardly use. Additional costs are related to the streaming, which is charged in Dataflow itself.
The simple example from the project cost us 34 € just because I forgot about it for a few days:
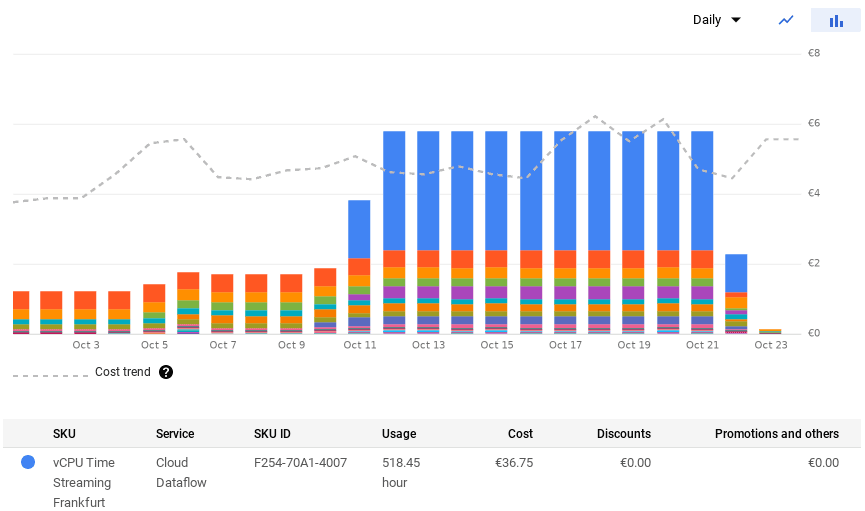
Changing to a Pub/Sub Topic to BigQuery setup, where messages are pushed rather than pulled, wouldn’t make a big difference. You would be paying extra for streaming as well. No matter how much I tried to google Dataflow cost optimization, I always paid way too much. It just seems to me that whoever wrote the template from Dataflow documentation did not care about the money. It should probably be mentioned somewhere in the documentation that the solution might be costly.
Subscribing to the topic with cloud function
Using the Python SDK for BigQuery is fairly simple. Writing a few lines for saving data to BigQuery table is not a difficult task:
errors = client.insert_rows_json(table_id, [event_data])
if not errors:
logging.info("New rows have been added.")
else:
raise ValueError("Encountered errors while inserting row: {}".format(errors)) The only thing that seems odd to me is that the method insert_rows_json does not throw exceptions for a wrong input. You have to check for errors in the return value.
We all know an excellent platform to run small pieces of code: That’s usually a job for Cloud Function. Pub/Sub has support for subscribing Cloud Function to the topic. You just need to provide a function to create an endpoint where to submit messages to. We prepared a terraform module for that. You can check it on Github.
Terraform resource for Cloud Function allows you to set subscription directly from the configuration:
resource "google_cloudfunctions_function" "function" {
...
event_trigger {
event_type = "google.pubsub.topic.publish"
resource = var.topic_name
}
...
}Of course, there are limitations: Any additional processing that takes a lot of time would add cost. Therefore, keep your messages reasonably small. Also, Cloud Functions will scale to infinity in case there is a large number of incoming messages. You should consider if the overall runtime of functions wouldn’t create additional cost.
Our experience is that we prefer Cloud Function over Dataflow. In most cases, the Cloud Function was almost ten times cheaper than the Dataflow job.
Conclusion
If you don’t have any additional workload to be done in Dataflow, avoid it for simple tasks like the one above. It’s a great tool that combines the power of Apache Beam with orchestration done by GCP. You have monitoring, provisioning and plenty of other tools for your job out of the box. That also means you are going to pay for them. Do you need to have all of those tools just for sending messages from Pub/Sub to BigQuery? Of course not.
Processing small size messages in Cloud Functions takes a reasonable amount of time. Your billing will get higher in direct relation to the messages processed by Cloud Function. That gives you a better insight into your billing. The conclusion is simple: don’t use complex tools for simple tasks. It all comes down to good research and finding good tools for the given job. That’s what architects do.





